How to lose $300+ million flipping property in a rising housing market with data-science*. A lesson in adverse selection.
*And also bad management. Still, pretty impressive.
Zillow lost millions using machine-learning
A few years ago, the online real-estate marketplace Zillow announced it would use “algorithms” to identify cheap properties that it could later flip for a handsome profit. Sounds obvious enough right? Surely with a big-data advantage, they will be able to do better in the housing market than the average punter? The CEO even predicted that the program could generate $20bn USD in annual revenue by 2024 at the latest1.
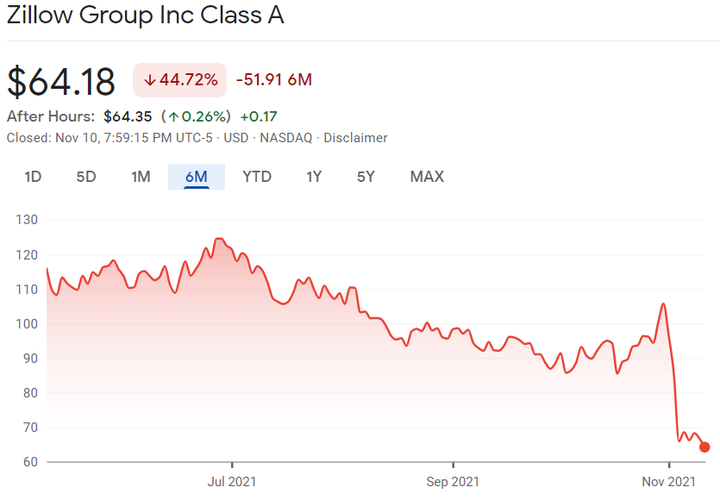
A few weeks ago, Zillow announced cutbacks of thousands of staff and losses of over $300 million USD and expects to lose even more2. Why? Because they “unintentionally” overpaid for houses that they are now struggling to sell. The effect on the companies stock price can be seen in the featured image above. This is particularly impressive in a market where house prices have only gone up.
 Source: FRED Median Sales Price of Houses Sold for the United States (MSPUS).
Source: FRED Median Sales Price of Houses Sold for the United States (MSPUS).
On a call with analysts regarding the program, the CEO stated
Fundamentally, we have been unable to predict the future pricing of homes to a level of accuracy that makes this a safe business to be in.
– The Zillow CEO and co-founder, Rich Barton.
But accuracy isn’t really the problem here. The problem is the competitive and adversarial nature of financial markets.
A simple explanation of adverse selection
Adverse selection can take many forms, but I think Wikipedia sums it up perfectly
adverse selection is a market situation where buyers and sellers have different information. The result is that participants with key information might participate selectively in trades at the expense of other parties who do not have the same information.
Let’s pretend you a making a market in jars of coins
To provide a concrete example, imagine you provide a service buying and selling glass jars full of coins.
- If someone wants to buy a jar from you, you need to estimate what the jar is worth and give them your ask price. You currently have an inventory of such jars.
- If someone wants to sell you a jar, you need to estimate what the jar is worth and give them a bid.
You need to estimate the value of these jars as accurately and quickly as possible, you don’t want someone else to beat you to the punch. Now because everything is ML/AI these days, you hire the best data-scientist you can and they build a state-of-the-art computer vision neural network to estimate the value of each jar. The model has great out-of-sample performance on an independent test/validation set so you might think that in aggregate, even though your model isn’t 100% perfect, you will be fine in the long run. The positive and negative errors will surely cancel out if you’ve fit a well-calibrated regression model. Right?
What ends up happening though?
- People selling jars know the sum value of the coins inside and only sell to you when you offer more than the value they know the jar to be worth.
- People buying jars take their time counting or use an even better model to value the jar and only buy it if you quote them less than the value they calculate or know the jar to be worth.
That’s a loss in both situations. The ‘model errors’ you assumed would cancel out don’t occur and you don’t break even. You very likely lose on every transaction. It didn’t matter how accurate your model was, people will only make a trade if it is favourable to them.
So what (probably) happened to Zillow?
Using the example above, replace jar with house and coin with whatever makes properties more or less valuable. The figures below show how Zillow get exploited based on their value estimates versus purchase values. Remember that Zillow used a model for housing purchase decisions, whilst sellers would likely have had far more useful insider-knowledge of the property they are selling.


The ultimate result is that Zillow bought low-value properties for a premium. Buy enough crappy properties that you are unable to shift for near your purchase price (let alone your predicted future price!) and you will end up in trouble pretty quickly.
Putting aside the issue of adverse selection, the proposition of using models to estimate even the ‘mean value’ of an asset like a house (or a stock) conditional on some features
Here’s Why Zillow Stock Plunged 20%—And Why It Won’t Flip Houses Anymore ↩︎
Provided you do your best to ensure that the training data contains data points that are representative of the yet to be observed, out-of-sample data. Suddenly changing the lighting conditions or even buying a better camera may cause issues if the training data does not contain data points reflecting this change. ↩︎